
Aarts et al. propose using multilevel analysis as a solution to dependency between observations often seen in biological neuroscience data.
A solution to dependency: using multilevel analysis to accommodate nested data.
For paper click here
Recently, concerns have been raised on an excess of false positive results contaminating the neuroscience literature. We speak of false positives when statistical tests pick up effects that are actually absent in reality (i.e., false finding, or “false alarm”). Reported causes for excesses of false positives that have been put forward are, among others, underpowered studies (Button et al) and choice of statistical methods (Nieuwenhuis et al.). Controlling the false positive rate is critical, since theoretical progress in the neuroscience field relies fundamentally on drawing correct conclusions from experimental research. Aarts and colleagues focus on another, often neglected, possible cause false positive results: neuroscience data often show dependency (i.e., “nesting‚) and failure to accommodate this dependency causes an excess of false positive results.
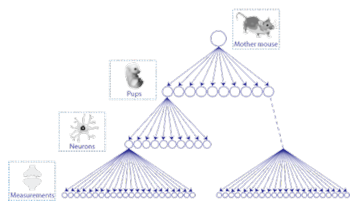 “Nested designs are experimental designs where multiple observations are collected from a single research object (e.g., multiple neurons from one animal). These nested designs are particularly common to the neuroscience field, as many research questions in neuroscience consider multiple layers of complexity: from protein complexes, synapses, and neurons, to neuronal networks, connected systems in the brain, and behavior‚, explains Emmeke Aarts. “We conducted a literature study to assess the generality of these nested designs in neuroscience. We scrutinized all molecular, cellular, and developmental neuroscience research articles published over the last 18 months in Science, Nature, Cell, Nature Neuroscience and every first issue of the month of Neuron. At least 53% of the 314 examined articles clearly reported nested data, which shows that nested data are indeed abundantly present in biological neuroscience‚, says Emmeke.
“Nested designs are experimental designs where multiple observations are collected from a single research object (e.g., multiple neurons from one animal). These nested designs are particularly common to the neuroscience field, as many research questions in neuroscience consider multiple layers of complexity: from protein complexes, synapses, and neurons, to neuronal networks, connected systems in the brain, and behavior‚, explains Emmeke Aarts. “We conducted a literature study to assess the generality of these nested designs in neuroscience. We scrutinized all molecular, cellular, and developmental neuroscience research articles published over the last 18 months in Science, Nature, Cell, Nature Neuroscience and every first issue of the month of Neuron. At least 53% of the 314 examined articles clearly reported nested data, which shows that nested data are indeed abundantly present in biological neuroscience‚, says Emmeke.
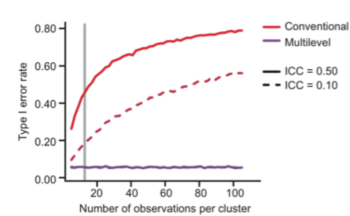 Why is nesting an issue? “Since observations taken from the same research object (e.g., brain, animal, cell) tend to be more similar than observations taken from different objects (e.g., due to natural variation between objects, and differences in measurement procedures or conditions), nested designs yield clusters of observations that cannot be considered independent. Conventional statistical methods, like the t-test and ANOVA, are often used to analyze these nested data, but these methods assume observations to be independent. The violation of this assumption results in an increase in the number of false positives. Depending on the number of observations per research object and the degree of dependence, the probability of incorrectly concluding that an effect is statistically significant (i.e., Type I error rate, usually set at 5%, i.e., α=.05) can increase to an alarming 80%.‚
Why is nesting an issue? “Since observations taken from the same research object (e.g., brain, animal, cell) tend to be more similar than observations taken from different objects (e.g., due to natural variation between objects, and differences in measurement procedures or conditions), nested designs yield clusters of observations that cannot be considered independent. Conventional statistical methods, like the t-test and ANOVA, are often used to analyze these nested data, but these methods assume observations to be independent. The violation of this assumption results in an increase in the number of false positives. Depending on the number of observations per research object and the degree of dependence, the probability of incorrectly concluding that an effect is statistically significant (i.e., Type I error rate, usually set at 5%, i.e., α=.05) can increase to an alarming 80%.‚
So why is the use of multilevel analysis better than using conventional statistical methods? “Multilevel analysis explicitly integrates in the statistical model the fact that multiple observations come from the same research object. As such, dependency between observations is accommodated in multilevel models and the Type I error rate is retained at the nominal level expressed by α‚, Emmeke explains. “Important to note for neuroscientists doing experimental research in nested designs is that the statistical power to detect an experimental effect hardly increases when one collects more observations per research object (e.g., more observations per cell): the power increases much more when one invests time and money in collecting data on more researcher objects (i.e., more unrelated cells)”, she adds.